别着急,坐和放宽
乱七八糟
语法
CodeBlock Loading...
求一个数二进制1的个数
CodeBlock Loading...
当后缀和不好维护的时候,考虑后缀和等于总和减去前缀和,转换成总和减前缀和
处理向上取整
快读快写
CodeBlock Loading...
二分
最大化查找(查找第一个<=q的数的下标)
CodeBlock Loading...
最小化查找(查找第一个>=q的数的下标)
CodeBlock Loading...
二分答案
CodeBlock Loading...
数学
位运算
消去x最后一位的1
CodeBlock Loading...
比如: 十进制数10的二进制为1010,9的二进制数为1001,那么(1010)&(1001)=1000,现在10的二进制中最后一位的1已经被消去
用途:
可以用来检测一个数是不是2的幂次。
如果一个数
x是2的幂次,那么x>0且x的二进制中只有一个1,所以用x&(x-1)把1消去,应该返回0,如果返回了非0值,证明不是2的幂次计算一个整数二进制中1的个数
因为1可以不断的通过
x&(x-1)这个操作消去,所以当最后的值变成0的时候,也就求出了二进制中1的个数如果将整数
A转换成整数B,需要改变多少个比特位.思考将整数A转换为B,如果A和B在第i(0<=i<32)个位上相等,则不需要改变这个BIT位,如果在第i位上不相等,则需要改变这个BIT位。所以问题转化为了A和B有多少个BIT位不相同。联想到位运算有一个异或操作,相同为0,相异为1,所以问题转变成了计算A异或B之后这个数中1的个数
其他常用操作:
| 功能 | 示例 | 位运算 |
|---|---|---|
| 去掉最后一位 | (101101->10110) | x shr 1 |
| 在最后加一个0 | (101101->1011010) | x shl 1 |
| 在最后加一个1 | (101101->1011011) | x shl 1+1 |
| 把最后一位变成1 | (101100->101101) | x or 1 |
| 把最后一位变成0 | (101101->101100) | x or 1-1 |
| 最后一位取反 | (101101->101100) | x xor 1 |
| 把右数第k位变成1 | (101001->101101,k=3) | x or (1 shl (k-1)) |
| 把右数第k位变成0 | (101101->101001,k=3) | x and not (1 shl (k-1)) |
| 右数第k位取反 | (101001->101101,k=3) | x xor (1 shl (k-1)) |
| 取末三位 | (1101101->101) | x and 7 |
| 取末k位 | (1101101->1101,k=5) | x and (1 shl k-1) |
| 取右数第k位 | (1101101->1,k=4) | x shr (k-1) and 1 |
| 把末k位变成1 | (101001->101111,k=4) | x or (1 shl k-1) |
| 末k位取反 | (101001->100110,k=4) | x xor (1 shl k-1) |
| 把右边连续的1变成0 | (100101111->100100000) | x and (x+1) |
| 把右起第一个0变成1 | (100101111->100111111) | x or (x+1) |
| 把右边连续的0变成1 | (11011000->11011111) | x or (x-1) |
| 取右边连续的1 | (100101111->1111) | (x xor (x+1)) shr 1 |
| 去掉右起第一个1的左边 | (100101000->1000) | x and (x xor (x-1)) |
利用二进制来枚举子集
假设我们现在有5个小球,上面分别标号了0,1,2,3,4代表这些小球的权值,现在要像你求出这些小球的权值可以组成的所有情况。
CodeBlock Loading...
异或操作
异或的性质:
CodeBlock Loading...
用途:
数组中,只有一个数出现一次,剩下都出现两次,找出出现一次的数
因为剩下的都出现了两次,那么异或值肯定为0,所以把所有的数异或起来得到的值就是那个数,可以做一下
nyoj-528找球号(三)个没有游标的天平,和n个秤砣,m个询问, 每次一个k,问可否秤出k这个重量。秤砣可以放两边。
bitset保存状态,用移位操作来转移。
CodeBlock Loading...待补充。
行列式计算
CodeBlock Loading...
欧拉筛
CodeBlock Loading...
逆元
加法中$a$元素的逆元为-a,在乘法运算中a的逆元为$a^-1$
逆元可以用乘法代替除法实现除法意义的取模运算

img
递推求逆元
CodeBlock Loading...
快速幂求逆元
CodeBlock Loading...
鸽巢原理
如果要把n + 1个物体放进n个盒子,那么至少有一个盒子包含两个或更多的物体
加强版
设$q1,q2,q3,q4.......qn$为正整数,如果将$q1,q2,q3,q4......qn - n + 1$个物体放入n个盒子内,那么或者第一个盒子内至少含有$q1$个物体或者第二个盒子内至少含有$q2$个物体..........第n个盒子内至少含有$q_n$个物体。
组合数
二项式定理
其中$\dbinom{n}{m}$ =
递推法
CodeBlock Loading...
快速幂
CodeBlock Loading...
欧拉函数
。
因为p是质数,所以$1$~$p^k$中间除了p的倍数之外所有数都与p互质,而p的倍数的个数是$p^k/p$
1.如果只求φ(n),唯一分解 那么我们就直接将n唯一分解处理出每一个n的素数,然后用通项公式就行了。 效率:O(√n)
CodeBlock Loading...
2.如果要求一个区域内的欧拉函数$φ(1 - n)$用唯一分解就太慢了,用到积性公式去做分解
CodeBlock Loading...
欧拉定理
若正整数a,n互质,则有$a^{φ(x)}\equiv 1 \pmod n$
如$m = 10,a = 3时,φ(10) = 4,3^4 = 81 \equiv 1\pmod n$
莫比乌斯函数
反演结论
裴蜀定理
在数论中,裴蜀定理是一个关于最大公约数(或最大公约式)的定理。裴蜀定理得名于法国数学家艾蒂安·裴蜀,说明了对任何整数a、b和它们的最大公约数d
有方程$ax + by = m$有解当且仅当m是d的倍数。裴蜀等式有解时必然有无穷多个整数解,每组解x、y都称为裴蜀数,可用辗转相除法求得。
素数测试与因式分解(Miller-Rabin & Pollard-Rho)
isprime函数判断素数,Pollard-Rho在factorize中在数组里存储因子
CodeBlock Loading...
博弈论(公平组合游戏(Impartial Combinatorial Games,ICG))
sg函数
其中x,y都表示某种状态,$x\to y$在这里表示x可以通过一次操作到y状态,mex表示一个集合中没有出现的最小数。例如$mex(\left{1,3,4\right}) = 2$,当sg(x) = 0时我们称之为必败态,相反,如果存在$sg(x) \neq 0$则称x为必胜态,说明此次存在策略使自己必定取胜,
sg定理
设置x和y为ICG的状态,则:$sg(x + y) = sg(x)\oplus sg(y)$可以推广出
利用sg定理,我们就可以轻松把单一游戏的情况推广到多个子游戏组合的情况下,例如Nim游戏就是在n堆石子的异或和为0的时候必败,否则必胜。
常用于打表的函数mex函数
CodeBlock Loading...
搜索
DFS
把根节点放进栈里 取出一个节点,进行处理 将此节点的子节点放入栈(没有子节点就不放) 判断栈是否为空。如果非空,返回第2步;如果为空,结束。
CodeBlock Loading...
BFS
BFS的基本思路是:
把根节点放进队列里 取出一个节点,进行处理 将此节点的子节点放入队列(没有子节点就不放) 判断队列是否为空。如果非空,返回第2步;如果为空,结束。
CodeBlock Loading...
快速幂
CodeBlock Loading...
字符串
KMP
1.求NEXT数组
CodeBlock Loading...
2.求是否匹配
CodeBlock Loading...
字符串哈希
19260817 //大质数
多项式哈希函数$f(s) = \sum_{i = 1}^ls[i]*b^{l - i}(Mod M)$ 其中$M$是一个素数
CodeBlock Loading...
(效率低下的版本)
进制哈希
进制哈希的核心便是给出一个固定进制𝑏𝑎𝑠𝑒,将一个串的每一个元素看做一个进制位上的数字,所以这个串就可以看做一个𝑏𝑎𝑠𝑒进制的数,那么这个数就是这个串的哈希值;则我们通过比对每个串的的哈希值,即可判断两个串是否相同
CodeBlock Loading...
多重哈希
CodeBlock Loading...
字典树
CodeBlock Loading...
AC自动机
动态规划
线性动态规划
最长各种序列
朴素做法
CodeBlock Loading...
二分优化
CodeBlock Loading...
背包问题
01背包
一个物品只能取一次
CodeBlock Loading...
完全背包
有无数个物品,可以任意取
CodeBlock Loading...
分组背包
有⼀些物品和⼀个容积为$m$的背包,把物品分成n组,其中第$i$组共$s[i]$ 种物品,第$k$种物品的体积为,价值为$w[i][k]$,
每组中只能选择⼀个物品,要求从$n$组中选出若⼲物品使其总价值最⼤且总体积不超过背包容积。
CodeBlock Loading...
多重背包
有$n$种物品和⼀个容积为$m$ 的背包,第$i$种物品的体积为$v[i]$ ,价值为$w[i]$,共$s[i]$个,要求从$n$种物品中
取出若⼲使其总价值最⼤且总体积不超过背包容积$m$.
朴素做法
CodeBlock Loading...
二进制拆分优化
CodeBlock Loading...
区间dp
区间类型动态规划是线性动态规划的拓展,它在分阶段划分问题时,与阶段中元素出现的顺序和由前一阶段的哪些元素合并而来有很大的关系.例如$f[i][j] = f[i][k] + f[k + 1][j]$,区间类动态规划的特点:
合并:即将两个或多个部分进行整合。
特征:能将问题分解成为两两合并的形式。
求解:对整个问题设最优值,枚举合并点,将问题分解成为左右两个部分,最后将左右两个部分的最优值进行合并得到原问题的最优值。
区间dp的做法比较固定,即枚举区间长度,再枚举左端点,之后枚举端点的断点进行转移
CodeBlock Loading...
树形dp
两种方向
- 1.根->叶(往往是在从叶往根dfs一遍之后(相当于预处理),再重新往下获取最后的答案。 )
- 2.叶->根(在回溯的时候从叶子节点往上更新信息)
难点
- 1.利用递归+记忆化搜索
- 2.细节多,从子树,从父亲,从兄弟,.......,有小的要处理的地方,脑子不清晰的时候做起来颇为恶心
- 状态表示和转移方程,也是真正难的地方。做到后面,树形DP的老套路都也就那么多,难的还是怎么能想出转移方程,各种DP做到最后都是这样!
状压dp
状压dp就是将状态压缩成二进制进行保存,是利用计算机二进制的性质来描述状态的一种dp方式。
泰难
数位dp
数位dp有个通用的套路,就是先采用前缀和思想,将求解“[𝑙,𝑟]这个区间内的满足约束的数的数量”,转化为“[1,𝑟]满足约束的数量 - 区间[1,𝑙−1]满足约束的数量。
所以我们最终要求解的问题通通转化为:[1,𝑥]中满足约束的数量,或者[0,𝑥]中的满足约束的数量(左边界取决于题目),然后将数字𝑥拆分为一个个数位
CodeBlock Loading...
求解区间$[L,R]上的所有数的数位和之和$,常常分解成$[0,R] - [0,L - 1]$之和
用dfs写法,用形参pos来表示当前枚举的位置,一般从高到低。
举例:假设x为4132,用“?”来表示暂未填写的数位,则现在填数状态为????,第一步我们得先填写第len位(最高位),我们只能填写0~4
若填写大于4的数码,显然不在我们的枚举范围里
如果填写4的话下面的数字还是会受到限制,下面的数字就不能填超过1的数字
如果填写0~3的话,剩下的数字就可以随便填写了,所以我们需要记录一个变量$limit$,表示在当前数位上是不是可以随意填写。
limit : bool值变量,表示枚举的第pos位是否受限制。该位为true表示取得数不能大于$a[pos]$,只有当$[pos + 1,len]$的位置填写的数都等于$a[i]$时,该值才为$true$,否则表示当前位没有限制,可以取到[0,R - 1],R - 1表示在R进制下最多能取到的数字。
当我们搜索到$pos = 0$的时候,表示所有数位都已经填写完毕了,每个“?”都被替换成了具体的数字,这可以作为一个递归边界,我们需要返回枚举填写的所有数位和sum,故dfs函数的形参还得添加:sum
sum: int型变量,表示当前$(len \to pos + 1)$的数位和。以上是普通的dfs搜索,而数位dp就是把相同的部分给去掉了
设置状态$f[pos][sum]表示位置[pos + 1,len]都已经填写完毕,且这些数位之和位sum的情况下,数位[1,pos]任意填写。$
CodeBlock Loading...
记忆化dfs函数常见形参
:int型变量,表示当前枚举的位置,一般从高到低
𝑙𝑖𝑚𝑖𝑡:bool型变量,表示枚举的第𝑝𝑜𝑠位是否受到限制,
为true表示取的数不能大于𝑎[𝑝𝑜𝑠],而只有在[𝑝𝑜𝑠+1,𝑙𝑒𝑛]的位置上填写的数都等于𝑎[𝑖]时该值才为true
否则表示当前位没有限制,可以取到[0,𝑅−1],因为𝑅进制的数中数位最多能取到的就是𝑅−1
- 𝑙𝑎𝑠𝑡:int型变量,表示上一位(第𝑝𝑜𝑠+1位)填写的值,往往用于约束了相邻数位之间的关系的题目
- 𝑙𝑒𝑎𝑑0:bool型变量,表示是否有前导零,即在𝑙𝑒𝑛→(𝑝𝑜𝑠+1)这些位置是不是都是前导零
基于常识,我们往往默认一个数没有前导零,也就是最高位不能为0,即不会写为000123,而是写为123
只有没有前导零的时候,才能计算0的贡献。
那么前导零何时跟答案有关?
- 统计0的出现次数
- 相邻数字的差值
- 以最高位为起点确定的奇偶位
- 𝑠𝑢𝑚:int型变量,表示当前𝑙𝑒𝑛→(𝑝𝑜𝑠+1)的数位和
- 𝑟:int型变量,表示整个数前缀取模某个数𝑚的余数
- 该参数一般会用在:约束中出现了能被𝑚整除
- 当然也可以拓展为数位和取模的结果
- 𝑠𝑡:int型变量,用于状态压缩,对一个集合的数在数位上的出现次数的奇偶性有要求时,其二进制形式就可以表示每个数出现的奇偶性
数据结构
并查集
常规并查集
CodeBlock Loading...
带权并查集
带权并查集可以存储节点的权值
CodeBlock Loading...
因为在路径压缩后父节点直接变为根节点,此时父节点的权值已经是父节点到根节点的权值了,将当前节点的权值加上原本父节点的权值,就得到当前节点到根节点的权值
CodeBlock Loading...
st表
形成
CodeBlock Loading...
原理如图
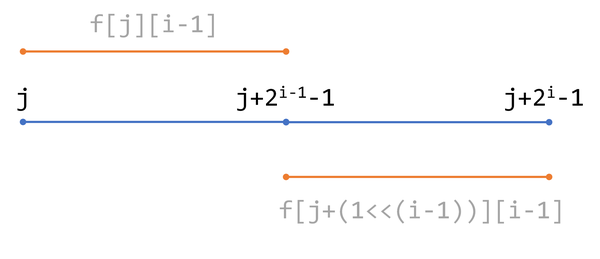
img
递推log
CodeBlock Loading...
在线查询
CodeBlock Loading...
模板
CodeBlock Loading...
链式前向星
CodeBlock Loading...
链式前向星的遍历
BFS
CodeBlock Loading...DFS
CodeBlock Loading...
树状数组
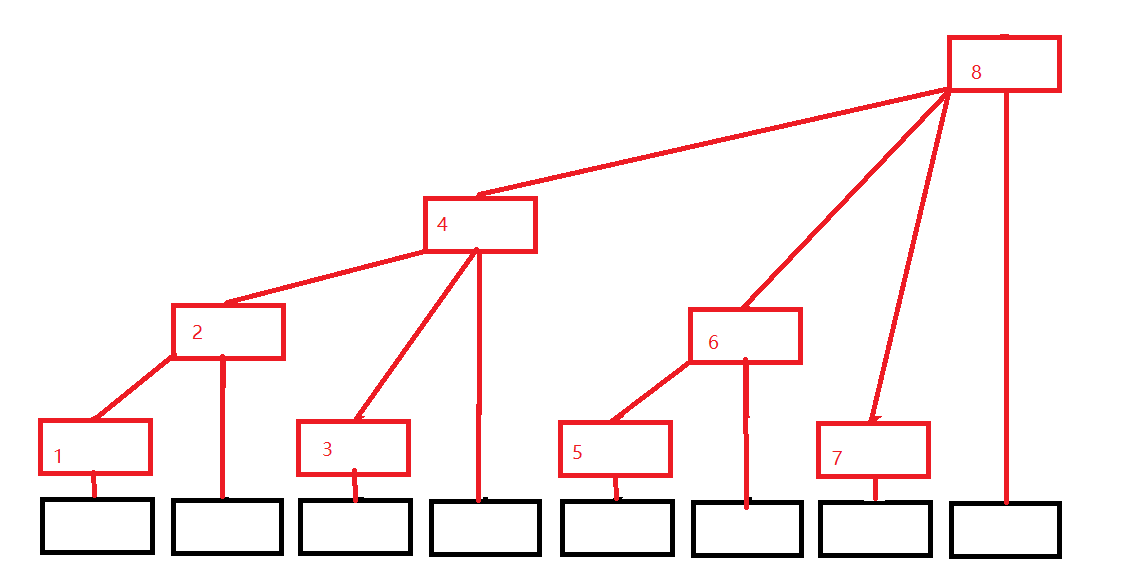
img
黑色数组代表原来的数组(下面用A[i]代替),红色结构代表我们的树状数组(下面用C[i]代替),每个位置只有一个方框,令每个位置存的就是子节点的值的和,则有$C[1] = A[1], C[2] = A[1] + A[2], C[3] = A[3], C[4] = A[1] + A[2] + A[3] + A[4],C[5] = A[5]$
我们要找前7项和,那么应该是$SUM = C[7] + C[6] + C[4]$;
CodeBlock Loading...
单点修改,区间查询
CodeBlock Loading...
区间修改,单点查询
区间修改需要用树状数组来存储差分数组,在树状数组的两端进行差分数组的修改,求和时直接求差分数组的前缀和就可以得到修改之后的数据点上的值
CodeBlock Loading...
线段树
线段树的基本结构和建树
线段树将每个长度不为$1$的区间划分成左右两个区间递归求解,把整个线段划分为一个树形结构,通过合并左右两区间信息来求得该区间的信息。这种数据结构可以方便的进行大部分的区间操作.
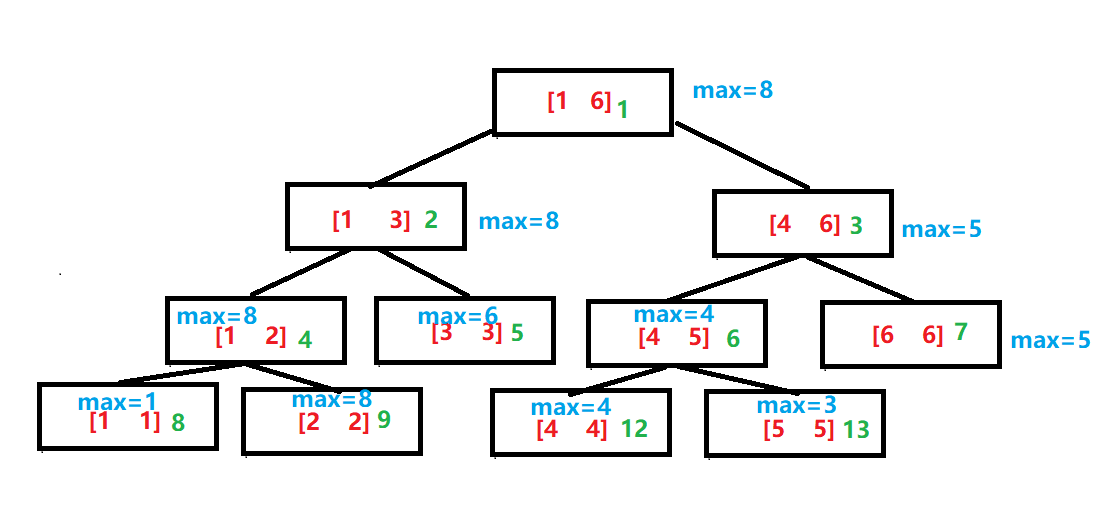
img
对于A[1:6] = {1,8,6,4,3,5}来说,线段树如上所示,红色代表每个结点存储的区间,蓝色代表该区间最值,绿色代表区间的下标。
可以发现,每个叶子结点的值就是数组的值,每个非叶子结点的度都为二,且左右两个孩子分别存储父亲一半的区间。每个父亲的存储的值也就是两个孩子存储的值的最大值。设父亲节点的下标为$fa$,左儿子的下标为$l$,右儿子节点下标为$r$,易得$l = 2fa,r = 2fa + 1$,因此线段树建树需要4*n的空间。
我们通常通过$k<<1$来寻找左孩子,通过$k>>1$来寻找右孩子
以下模板求的是区间最大值
区间最大值模板
CodeBlock Loading...
区间和模板
CodeBlock Loading...
区间加,乘
CodeBlock Loading...
zkw线段树
理论上能放$(0,2^n)$的数,只能查询$(1,2^n - 2)$的范围
非递归方式建树,建的是一个满二叉树
CodeBlock Loading...
单点修改
CodeBlock Loading...
区间查询
CodeBlock Loading...
区间修改
CodeBlock Loading...
区间修改的查询
CodeBlock Loading...
区间加,区间查询最大值的模板
CodeBlock Loading...
CodeBlock Loading...
扫描线(不太理解modify部分)
CodeBlock Loading...
莫队
如果能在$O(1)$中从$[l,r]$的答案转移到$[l - 1,r],[l + 1,r],[l,r + 1],[l,r - 1]$这四个与之紧邻的区间的答案,则可以考虑使用莫队
例题:给出一个序列和若干查询l,r,问[l,r]中有多少个不同的数。
优化1
在q1和q2两个区间内进行指针的左右移动,如果左指针在查询区间左边,左指针右移,如果左指针在查询左区间右边,左指针右移,如果右指针在查询右端点右边,右指针左移,否则右移。
CodeBlock Loading...
优化2
预处理
把大小为n的序列分成$\sqrt n 1 \to \sqrt n$编号,然后根据这个对查询区间进行排序。一种方法是把查询区间按照左端点所在的块进行排序,如果左端点所在块相同,再按照右端点排序。排完序后我们再进行左右指针跳来跳去的操作
CodeBlock Loading...
CodeBlock Loading...
图论
基础概念
在$G(V,E)中,V作为点集,E作为边集合$
简单图
自环
重边
在无向图中$(u,v)$和$(v,u)$算一组重边,而在有向图中,$u\to v$和$v \to u$不为重边。
简单图
简单图 (simple graph):若一个图中没有自环和重边,它被称为简单图。具有至少两个顶点的简单无向图中一定存在度相同的结点。
拓扑排序
CodeBlock Loading...
单元最短路径问题(SSSP)
(x,y,z)描述x出发到达y且长度为z的有向边,dist[i]表示从起点1到节点i的最短路径的长度
Dijkstra算法
1.初始化dist[1] = 0,其余节点的dist为正无穷大
2.找出一个未被标记的,dist最小的节点x,然后标记节点x
3.扫描节点所有的出边(x,y,z),若dist[y] > dist + z,则用后者更新dist[y]
O^2做法
CodeBlock Loading...
二叉堆优化(mlogn)
CodeBlock Loading...
- 给定一张图,对于图中的某一条边(x,y,z),有dist[y] <= dist + z成立,称该边满足三角形不等式。若所有边都满足三角形不等式,则dist数组就是所求最短路。
- 基于迭代方法的Bellman-Ford算法:
1.建立一个队列一开始只有起点1
2.取出队头节点x,扫描他的所有出边(x,y,z),若dist[y]>dist + z则用dist + z 来更新dist[y]
SPFA(Bellman-Ford算法优化)
CodeBlock Loading...
(最近公共祖先)LCA
求两个点的最近公共祖先
CodeBlock Loading...
最小生成树
Prim算法
CodeBlock Loading...
Kruscal算法
CodeBlock Loading...
匈牙利算法
(目的是尽可能更多的匹配)
把二分图分为A,B两个集合,依次枚举A中的每个点,试图在B集合中找到一个匹配。对于A集合中一个点x,假设B集合中有一个与其相连的点y,若y暂时还没有匹配点,那么x可以与y匹配:找到;
如果y已经有匹配点了,则回溯y匹配的点z,尝试着为z找一个除了y之外的匹配点,如果找到了,x和y可以匹配,否则两者无法匹配。
CodeBlock Loading...
最小点覆盖
想找到最少的点的数量,使得二分图的所有边都有一个端点在这些点中(就是删除掉这么多数量的点能够让所有的边能消失)
根据König定理可以得知,一个二分图中的最大匹配数等于这个图中的最小点覆盖数。于是得解。
Tarjan算法
求割点
割点的性质:
1.如果T的根节点是一个割点,当且仅当根节点有两个或者更多的子节点
2.T的非根节点cur是割点,当且仅当cur存在一个子节点nxt,nxt和他的后代都没有回退边连向cur的祖先
CodeBlock Loading...
点双连通分量(vDcc)
点双连通分量:一个图中,点双连通的极大子图为一个点双连通分量。
性质:我们使用dfs找到一个割点之后,实际上已经完成了一个对于一个点双连通分量的访问。
使用一个栈来保存dfs的顺序。
和割点有关系
边双连通分量(eDCC)
性质:low值相同的点,必定在一个边双里。
强连通图缩点
强连通图指的是一张有向图内每个点一点都能到达任意的一个点
如果任意两点间存在路径,此称此图具有连通性,如下的图结构具有连通性。提及连通性,就不得不说连通分量,通俗而言,指结构中有多少个连通通道,如下的图结构只有一个连通通道,也就是一个连通分量,所有节点在这个连通通道上都能互通。
强连通是有向图的特定概念。有向图中,任意两点之间都可以连通,则认定此有向图为强连通图
若dfn[u] == low[u]这说明了𝑢点及𝑢点之下的所有子节点没有边是指向u的祖先的了,即我们之前说的𝑢点与它的子孙节点构成了一个最大的强连通图即强连通分量.
CodeBlock Loading...
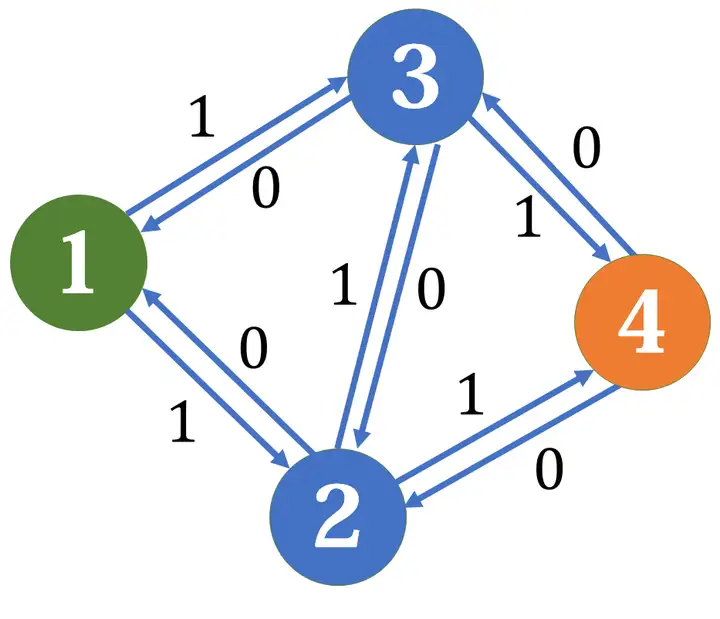
网络最大流
拥有源点还有一个汇点,其上的边权称为容量,网络流中常见的问题就是网络最大流,假定从源点流出的流量足够多,求能够流入汇点的最大流量
解决这个问题最常用的是Ford-Fulkerson算法及其优化。
img
FF算法通过增广路和反向边(相当于一种反悔机制)
Ford-Fulkerson
CodeBlock Loading...
Edmond-Karp
CodeBlock Loading...
Dinic算法
CodeBlock Loading...
最小割
一个网络的割是这样一个边集,如果把这个集合的边删去,这个网络就不再连通,这个边集中边的容量和被称为割的容量,容量最小的割被称为最小割
最大流最小割定理
对于一个容量网络,其最大流等于最小割的容量
路径覆盖问题
路径覆盖问题是在DAG(有向无环图)上进行的,找出尽可能少的一系列路径,使得这些路径经过DAG上所有的点恰好一次。可以用网络流来解决这个问题,
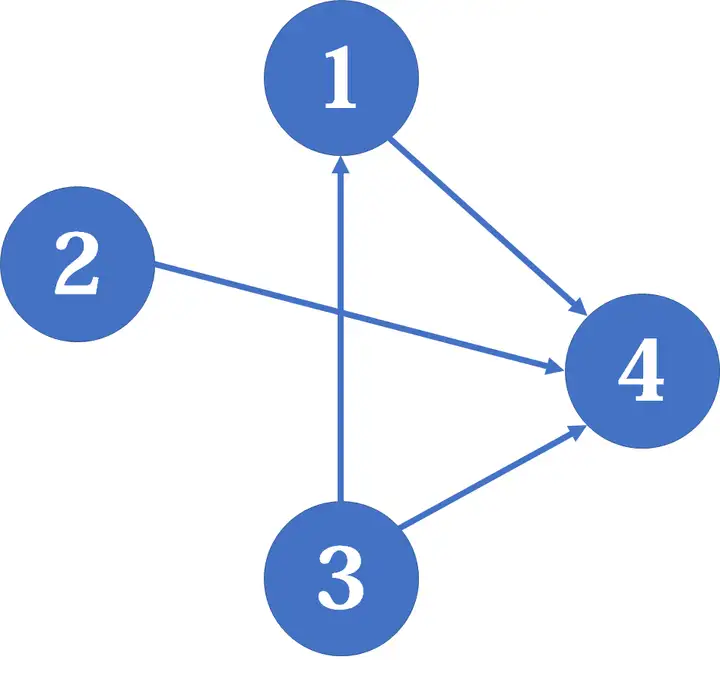
img
以这张图片为例,建立网络流模型,把原图中的每个点拆成两个点,其中一个点与源点相连,另一个点与汇点相连。(对于点x,可以把从它拆出去的点记为x+n)
计算几何
二维几何基础
CodeBlock Loading...
旋转卡壳(求凸包的直径)
这里模板求的是直径的平方
CodeBlock Loading...
圆和球
CodeBlock Loading...
海伦公式形态的四面体体积公式
一般海伦公式:公式中a,b,c分别为三角形三边长,p为半周长,S为三角形的面积。
以下内容转自维基百科
如果U、V、W、u、v、w是四面体的六条边长(U、V、W构成四面体的其中一个三角形面,而u是与U相对的棱,v是与V相对的棱,w是与W相对的棱),则四面体体积

这里
